
MySQL面经[下]
索引
Innodb和Myisam引擎
**Myisam:**支持表锁,适合读密集的场景,不支持外键,不支持事务,索引与数据在不同的文件
**Innodb:**支持行、表锁,默认为行锁,适合并发场景,支持外键,支持事务,索引与数据同一文件
哈希索引
哈希索引用索引列的值计算该值的hashCode,然后在hashCode相应的位置存执该值所在行数据的物理位置,因为使用散列算法,因此访问速度非常快,但是一个值只能对应一个hashCode,而且是散列的分布方式,因此哈希索引不支持范围查找和排序的功能。
MySQL中存在哪些索引
MySQL 提供了多种类型的索引,每种索引都有其特定的用途和特点。下面是对这些索引的详细解释:
NORMAL索引
NORMAL 索引是 MySQL 中最常见和默认的索引类型,适用于大多数情况下的数据检索。NORMAL 索引包括主键索引(Primary Key Index)、唯一索引(Unique Index)、普通索引(Index)和组合索引(Composite Index)。
特点
- 数据类型:适用于大多数数据类型,包括整数、字符串和日期等。
- 性能:提高数据检索的速度,通过索引可以更快地找到数据行。
- 用途广泛:可以用于 WHERE 子句、JOIN 操作、排序和分组等。
主键索引(Primary Key Index)
- 特点:
- 主键索引是一种唯一索引,每个表只能有一个主键。
- 主键列不允许为空。
- 主键索引自动创建在表的主键列上。
- 用途:
- 唯一标识表中的每一行。
- 常用于关系型数据库中的外键约束。
- 创建方式:
- 在创建表时定义主键,或者在已有表上添加主键。
CREATE TABLE example (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
PRIMARY KEY (id)
);普通索引(Index)
- 特点:
- 普通索引用于加速数据检索,不保证唯一性。
- 可以在任意列上创建普通索引。
- 用途:
- 提高查询性能,特别是在 WHERE 子句中频繁使用的列。
- 创建方式:
- 可以在创建表时定义,也可以在已有表上添加。
CREATE TABLE example (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
INDEX (name)
);组合索引(Composite Index)
组合索引(Composite Index),也称为复合索引或多列索引,是在多个列上创建的索引。组合索引可以提高涉及多个列的查询性能,特别是在 WHERE 子句中使用多列进行过滤时。
组合索引的特点
多列组合:组合索引由多个列组合而成,索引中的列顺序非常重要。MySQL 会按照索引中列的顺序进行排序和查找。
覆盖索引:如果查询的所有列都包含在索引中,那么 MySQL 可以直接从索引中获取数据,而不需要访问数据表,这称为覆盖索引(Covering Index)。
前缀匹配原则:组合索引遵循前缀匹配原则,即只有在查询条件中包含索引前缀列时,索引才会被有效利用。例如,组合索引 (A, B, C) 可以用于 (A)、(A, B) 和 (A, B, C) 的查询。
创建组合索引
组合索引可以在创建表时定义,也可以在已有表上添加。
创建表时定义组合索引
CREATE TABLE example (
id INT NOT NULL AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INT,
PRIMARY KEY (id),
INDEX name_index (first_name, last_name)
);在已有表上添加组合索引
CREATE INDEX name_index ON example (first_name, last_name);使用组合索引的查询示例
假设我们有一个包含 first_name 和 last_name 的组合索引,我们可以进行以下查询:
使用组合索引中的第一列
SELECT * FROM example WHERE first_name = 'John';使用组合索引中的前两列
SELECT * FROM example WHERE first_name = 'John' AND last_name = 'Doe';使用组合索引中的所有列
SELECT * FROM example WHERE first_name = 'John' AND last_name = 'Doe' AND age = 30;注意,尽管组合索引包含了多个列,但如果查询条件中不包含索引的前缀部分,索引将无法被有效利用:
-- 无法有效利用组合索引
SELECT * FROM example WHERE last_name = 'Doe';组合索引的优点
- 提高查询性能:组合索引可以显著提高涉及多列的查询性能,特别是在 WHERE 子句中使用多列进行过滤时。
- 减少索引数量:通过创建组合索引,可以减少单列索引的数量,从而降低索引维护成本。
- 支持覆盖索引:组合索引可以支持覆盖索引,从而减少数据表的访问次数,提高查询效率。
组合索引的缺点
- 占用更多空间:组合索引通常比单列索引占用更多的存储空间。
- 维护成本较高:插入、更新和删除操作需要更新组合索引,因此维护成本较高。
- 选择列顺序需要谨慎:索引的列顺序非常重要,选择不当可能会导致索引无法被有效利用。
总结
组合索引在优化多列查询方面非常有效,但在创建组合索引时需要仔细考虑查询
FULLTEXT索引
全文索引(Full-Text Index)
- 特点:
- 全文索引用于全文搜索,适用于 CHAR、VARCHAR 和 TEXT 列。
- 支持自然语言模式和布尔模式的全文搜索。
- 用途:
- 提高对文本数据的搜索效率,特别适用于大文本字段的搜索。
- 创建方式:
- 可以在创建表时定义,也可以在已有表上添加。
CREATE TABLE example (
id INT NOT NULL AUTO_INCREMENT,
content TEXT,
FULLTEXT (content)
);- 查询示例:
SELECT * FROM example WHERE MATCH (content) AGAINST ('some text');UNIQUE索引
唯一索引(Unique Index)
- 特点:
- 唯一索引保证列中的值是唯一的,但允许有空值。
- 每个表可以有多个唯一索引。
- 用途:
- 确保列中的数据唯一性,防止重复数据。
- 创建方式:
- 可以在创建表时定义,也可以在已有表上添加。
CREATE TABLE example (
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(50),
UNIQUE (email)
);SPATIAL 索引
SPATIAL 索引是专门用于地理空间数据的索引类型。它主要用于存储和检索几何数据,如点、线、多边形等,适用于 GIS(地理信息系统)应用。
特点
- 数据类型:适用于几何数据类型,如 POINT、LINESTRING 和 POLYGON。
- 存储引擎:通常与 MyISAM 存储引擎一起使用,但从 MySQL 5.7.5 开始,InnoDB 也支持
SPATIAL索引。 - 查询性能:显著提高地理空间数据的查询性能,例如范围查询和空间关系查询。
示例
创建一个包含 SPATIAL 索引的表:
CREATE TABLE spatial_example (
id INT NOT NULL AUTO_INCREMENT,
location POINT NOT NULL,
SPATIAL INDEX (location)
) ENGINE=MyISAM;插入几何数据:
INSERT INTO spatial_example (location) VALUES (POINT(1.0, 1.0)), (POINT(2.0, 2.0));查询示例:
SELECT id FROM spatial_example WHERE MBRContains(GeomFromText('Polygon((0 0, 3 0, 3 3, 0 3, 0 0))'), location);注意事项
- 限制:在 MySQL 中,SPATIAL 索引不支持 NULL 值。
- 引擎支持:确保使用支持 SPATIAL 索引的存储引擎,如 MyISAM 或 InnoDB(从 MySQL 5.7.5 开始)。
B+树索引
优点:
B+树的磁盘读写代价低,更少的查询次数,查询效率更加稳定,有利于对数据库的扫描
B+树是B树的升级版,B+树只有叶节点存放数据,其余节点用来索引。索引节点可以全部加入内存,增加查询效率,叶子节点可以做双向链表,从而提高范围查找的效率,增加的索引的范围。
在大规模数据存储的时候,红黑树往往出现由于树的深度****过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。所以,只要我们通过某种较好的树结构减少树的结构尽量减少树的高度,B树与B+树可以有多个子女,从几十到上千,可以降低树的高度。
磁盘预读原理:将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
创建索引
CREATE [UNIQUE | FULLTEXT] INDEX 索引名 ON 表名(字段名) [USING 索引方法];说明:UNIQUE:可选。表示索引为唯一性索引。FULLTEXT:可选。表示索引为全文索引。INDEX和KEY:用于指定字段为索引,两者选择其中之一就可以了,作用是一样的。索引名:可选。给创建的索引取一个新名称。字段名1:指定索引对应的字段的名称,该字段必须是前面定义好的字段。注:索引方法默认使用B+TREE。聚簇索引和非聚簇索引
**聚簇索引:**将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据(主键索引)
**非聚簇索引:**将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置(辅助索引)
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
最左前缀问题
最左前缀原则主要使用在联合索引中,联合索引的B+Tree是按照第一个关键字进行索引排列的。
联合索引的底层是一颗B+树,只不过联合索引的B+树节点中存储的是键值。由于构建一棵B+树只能根据一个值来确定索引关系,所以数据库依赖联合索引最左的字段来构建。
采用>、<等进行匹配都会导致后面的列无法走索引,因为通过以上方式匹配到的数据是不可知的。
SQL语句的执行过程
查询语句:
select * from student A where A.age='18' and A.name='张三';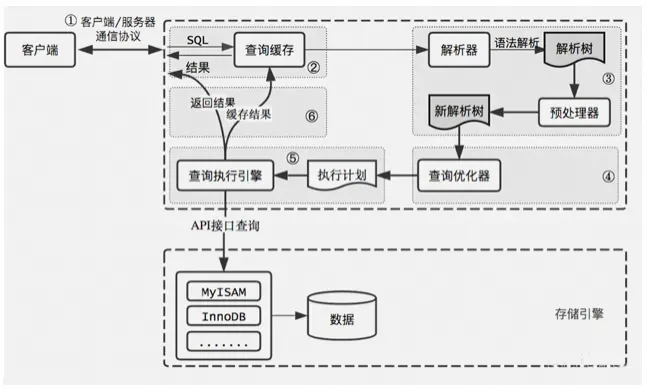
结合上面的说明,我们分析下这个语句的执行流程:
①通过客户端/服务器通信协议与 MySQL 建立连接。并查询是否有权限
②Mysql8.0之前开看是否开启缓存,开启了 Query Cache 且命中完全相同的 SQL 语句,则将查询结果直接返回给客户端;
③由解析器进行语法语义解析,并生成解析树。如查询是select、表名tb_student、条件是id='1'
④查询优化器生成执行计划。根据索引看看是否可以优化
⑤查询执行引擎执行 SQL 语句,根据存储引擎类型,得到查询结果。若开启了 Query Cache,则缓存,否则直接返回。
回表查询和覆盖索引
普通索引(唯一索引+联合索引+全文索引)需要扫描两遍索引树
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
**覆盖索引:**主键索引==聚簇索引==覆盖索引
如果where条件的列和返回的数据在一个索引中,那么不需要回查表,那么就叫覆盖索引。
**实现覆盖索引:**常见的方法是,将被查询的字段,建立到联合索引里去。
JOIN查询
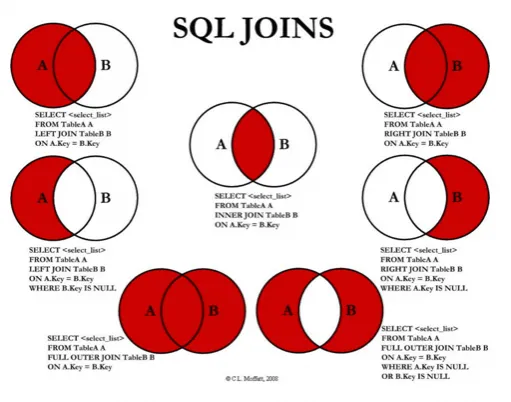
left join(左联接) 返回包括左表中的所有记录和右表中关联字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中关联字段相等的记录
inner join(等值连接) 只返回两个表中关联字段相等的行
集群
MySQl主从复制
**原理:**将主服务器的binlog日志复制到从服务器上执行一遍,达到主从数据的一致状态。
**过程:**从库开启一个I/O线程,向主库请求Binlog日志。主节点开启一个binlog dump线程,检查自己的二进制日志,并发送给从节点;从库将接收到的数据保存到中继日志(Relay log)中,另外开启一个SQL线程,把Relay中的操作在自身机器上执行一遍
优点:
- 作为备用数据库,并且不影响业务
- 可做读写分离,一个写库,一个或多个读库,在不同的服务器上,充分发挥服务器和数据库的性能,但要保证数据的一致性
**binlog记录格式:**statement、row、mixed
基于语句statement的复制、基于行row的复制、基于语句和行(mix)的复制。其中基于row的复制方式更能保证主从库数据的一致性,但日志量较大,在设置时考虑磁盘的空间问题。
数据一致性问题
"主从复制有延时",这个延时期间读取从库,可能读到不一致的数据。
缓存记录写key法:
在cache里记录哪些记录发生过的写请求,来路由读主库还是读从库
异步复制:
在异步复制中,主库执行完操作后,写入binlog日志后,就返回客户端,这一动作就结束了,并不会验证从库有没有收到,完不完整,所以这样可能会造成数据的不一致。
半同步复制:
当主库每提交一个事务后,不会立即返回,而是等待其中一个从库接收到Binlog并成功写入Relay-log中才返回客户端,通过一份在主库的Binlog,另一份在其中一个从库的Relay-log,可以保证了数据的安全性和一致性。
全同步复制:
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
集群架构
Keepalived + VIP + MySQL 主从/双主
当写节点 Master db1 出现故障时,由 MMM Monitor 或 Keepalived 触发切换脚本,将 VIP 漂移到可用的 Master db2 上。当出现网络抖动或网络分区时,MMM Monitor 会误判,严重时来回切换写 VIP 导致集群双写,当数据复制延迟时,应用程序会出现数据错乱或数据冲突的故障。有效避免单点失效的架构就是采用共享存储,单点故障切换可以通过分布式哨兵系统监控。
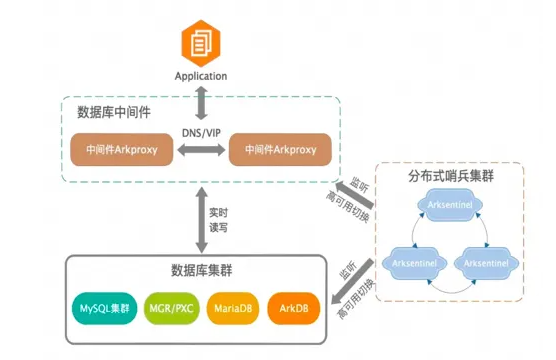
**架构选型:**MMM 集群 -> MHA集群 -> MHA+Arksentinel。
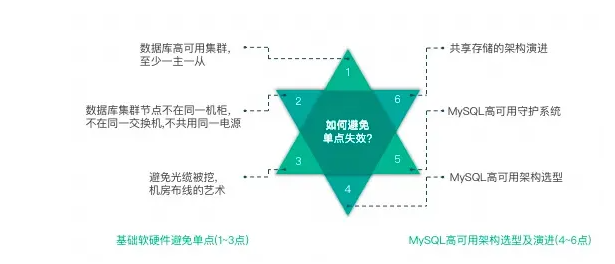
故障转移和恢复
转移方式及恢复方法
1. 虚拟IP或DNS服务 (Keepalived +VIP/DNS 和 MMM 架构)问题:在虚拟 IP 运维过程中,刷新ARP过程中有时会出现一个 VIP 绑定在多台服务器同时提供连接的问题。这也是为什么要避免使用 Keepalived+VIP 和 MMM 架构的原因之一,因为它处理不了这类问题而导致集群多点写入。
2. 提升备库为主库(MHA、QMHA)尝试将原 Master 设置 read_only 为 on,避免集群多点写入。借助 binlog server 保留 Master 的 Binlog;当出现数据延迟时,再提升 Slave 为新 Master 之前需要进行数据补齐,否则会丢失数据。
分库分表
如何进行分库分表
分表用户id进行分表,每个表控制在300万数据。
分库根据业务场景和地域分库,每个库并发不超过2000
Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是各个系统都需要耦合 Sharding-jdbc 的依赖,升级比较麻烦
Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了
水平拆分:一个表放到多个库,分担高并发,加快查询速度
- id保证业务在关联多张表时可以在同一库上操作
- range方便扩容和数据统计
- hash可以使得数据更加平均
**垂直拆分:**一个表拆成多个表,可以将一些冷数据拆分到冗余库中
不是写瓶颈优先进行分表
- 分库数据间的数据无法再通过数据库直接查询了。会产生深分页的问题
- 分库越多,出现问题的可能性越大,维护成本也变得更高。
- 分库后无法保障跨库间事务,只能借助其他中间件实现最终一致性。
分库首先需考虑满足业务最核心的场景:
1、订单数据按用户分库,可以提升用户的全流程体验
2、超级客户导致数据倾斜可以使用最细粒度唯一标识进行hash拆分
3、按照最细粒度如订单号拆分以后,数据库就无法进行单库排重了
三个问题:
富查询:采用分库分表之后,如何满足跨越分库的查询?使用ES的宽表
借助分库网关+分库业务虽然能够实现多维度查询的能力,但整体上性能不佳且对正常的写入请求有一定的影响。业界应对多维度实时查询的最常见方式便是借助 ElasticSearch;
数据倾斜:数据分库基础上再进行分表;
分布式事务:跨多库的修改及多个微服务间的写操作导致的分布式事务问题?
深分页问题:按游标查询,或者叫每次查询都带上上一次查询经过排序后的最大 ID;
如何将老数据进行迁移
双写不中断迁移
- 线上系统里所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改;
- 系统部署以后,还需要跑程序读老库数据写新库,写的时候需要判断updateTime;
- 循环执行,直至两个库的数据完全一致,最后重新部署分库分表的代码就行了;
系统性能的评估及扩容
和家亲目前有1亿用户:场景 10万写并发,100万读并发,60亿数据量
设计时考虑极限情况,32库*32表~64个表,一共1000 ~ 2000张表
- 支持3万的写并发,配合MQ实现每秒10万的写入速度
- 读写分离6万读并发,配合分布式缓存每秒100读并发
- 2000张表每张300万,可以最多写入60亿的数据
- 32张用户表,支撑亿级用户,后续最多也就扩容一次
动态扩容的步骤
- 推荐是 32 库 * 32 表,对于我们公司来说,可能几年都够了。
- 配置路由的规则,uid % 32 = 库,uid / 32 % 32 = 表
- 扩容的时候,申请增加更多的数据库服务器,呈倍数扩容
- 由 DBA 负责将原先数据库服务器的库,迁移到新的数据库服务器上去
- 修改一下配置,重新发布系统,上线,原先的路由规则变都不用变
- 直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。
如何生成自增的id主键
- 使用redis可以
- 并发不高可以单独起一个服务,生成自增id
- 设置数据库step自增步长可以支撑水平伸缩
- UUID适合文件名、编号,但是不适合做主键
- snowflake雪花算法,综合了41时间(ms)、10机器、12序列号(ms内自增)
其中机器预留的10bit可以根据自己的业务场景配置。
线上故障及优化
更新失败 | 主从同步延时
以前线上确实处理过因为主从同步延时问题而导致的线上的 bug,属于小型的生产事故。
是这个么场景。有个同学是这样写代码逻辑的。先插入一条数据,再把它查出来,然后更新这条数据。在生产环境高峰期,写并发达到了 2000/s,这个时候,主从复制延时大概是在小几十毫秒。线上会发现,每天总有那么一些数据,我们期望更新一些重要的数据状态,但在高峰期时候却没更新。用户跟客服反馈,而客服就会反馈给我们。
我们通过 MySQL 命令:
show slave status查看 Seconds_Behind_Master ,可以看到从库复制主库的数据落后了几 ms。
一般来说,如果主从延迟较为严重,有以下解决方案:
- 分库,拆分为多个主库,每个主库的写并发就减少了几倍,主从延迟可以忽略不计。
- 重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到。
- 如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库或者延迟查询。主从复制延迟一般不会超过50ms
应用崩溃 | 分库分表优化
我们有一个线上通行记录的表,由于数据量过大,进行了分库分表,当时分库分表初期经常产生一些问题。典型的就是通行记录查询中使用了深分页,通过一些工具如MAT、Jstack追踪到是由于sharding-jdbc内部引用造成的。
通行记录数据被存放在两个库中。如果没有提供切分键,查询语句就会被分发到所有的数据库中,比如查询语句是 limit 10、offset 1000,最终结果只需要返回 10 条记录,但是数据库中间件要完成这种计算,则需要 (1000+10)*2=2020 条记录来完成这个计算过程。如果 offset 的值过大,使用的内存就会暴涨。虽然 sharding-jdbc 使用归并算法进行了一些优化,但在实际场景中,深分页仍然引起了内存和性能问题。
这种在中间节点进行归并聚合的操作,在分布式框架中非常常见。比如在 ElasticSearch 中,就存在相似的数据获取逻辑,不加限制的深分页,同样会造成 ES 的内存问题。
业界解决方案:
方法一:全局视野法
(1)将order by time offset X limit Y,改写成order by time offset 0 limit X+Y
(2)服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录
这种方法随着翻页的进行,性能越来越低。
方法二:业务折衷法-禁止跳页查询
(1)用正常的方法取得第一页数据,并得到第一页记录的time_max
(2)每次翻页,将order by time offset X limit Y,改写成order by time where time>$time_max limit Y
以保证每次只返回一页数据,性能为常量。
方法三:业务折衷法-允许模糊数据
(1)将order by time offset X limit Y,改写成order by time offset X/N limit Y/N
方法四:二次查询法
(2)将order by time offset X limit Y,改写成order by time offset X/N limit Y
(3)找到最小值time_min
(4)between二次查询,order by time between timeminandtime_i_max
(5)设置虚拟time_min,找到time_min在各个分库的offset,从而得到time_min在全局的offset
(6)得到了time_min在全局的offset,自然得到了全局的offset X limit Y
查询异常 | SQL调优
分库分表前,有一段用用户名来查询某个用户的 SQL 语句:
select * from user where name = "xxx" and community="other";为了达到动态拼接的效果,这句 SQL 语句被一位同事进行了如下修改。他的本意是,当 name 或者 community 传入为空的时候,动态去掉这些查询条件。这种写法,在 MyBaits 的配置文件中,也非常常见。大多数情况下,这种写法是没有问题的,因为结果集合是可以控制的。但随着系统的运行,用户表的记录越来越多,当传入的 name 和 community 全部为空时,悲剧的事情发生了:
select * from user where 1=1数据库中的所有记录,都会被查询出来,载入到 JVM 的内存中。由于数据库记录实在太多,直接把内存给撑爆了。由于这种原因引起的内存溢出,发生的频率非常高,比如导入Excel文件时。
通常的解决方式是强行加入分页功能,或者对一些必填的参数进行校验
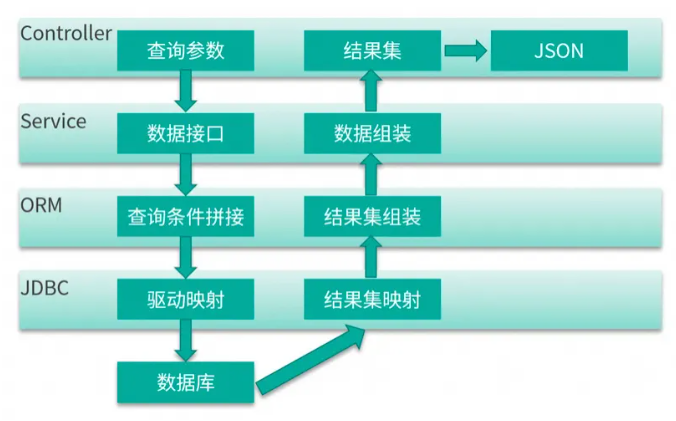
Controller 层
现在很多项目都采用前后端分离架构,所以 Controller 层的方法,一般使用 @ResponseBody 注解,把查询的结果,解析成 JSON 数据返回。这在数据集非常大的情况下,会占用很多内存资源。假如结果集在解析成 JSON 之前,占用的内存是 10MB,那么在解析过程中,有可能会使用 20M 或者更多的内存
因此,保持结果集的精简,是非常有必要的,这也是 DTO(Data Transfer Object)存在的必要。互联网环境不怕小结果集的高并发请求,却非常恐惧大结果集的耗时请求,这是其中一方面的原因。
Service 层
Service 层用于处理具体的业务,更加贴合业务的功能需求。一个 Service,可能会被多个 Controller 层所使用,也可能会使用多个 dao 结构的查询结果进行计算、拼装。
int getUserSize() {
List<User> users = dao.getAllUser();
return null == users ? 0 : users.size();
}代码review中发现了定时炸弹,这种在数据量达到一定程度后,才会暴露问题。
ORM 层
比如使用Mybatis时,有一个批量导入服务,在 MyBatis 执行批量插入的时候,竟然产生了内存溢出,按道理这种插入操作是不会引起额外内存占用的,最后通过源码追踪到了问题。
这是因为 MyBatis 循环处理 batch 的时候,操作对象是数组,而我们在接口定义的时候,使用的是 List;当传入一个非常大的 List 时,它需要调用 List 的 toArray 方法将列表转换成数组(浅拷贝);在最后的拼装阶段,又使用了 StringBuilder 来拼接最终的 SQL,所以实际使用的内存要比 List 多很多。
事实证明,不论是插入操作还是查询动作,只要涉及的数据集非常大,就容易出现问题。由于项目中众多框架的引入,想要分析这些具体的内存占用,就变得非常困难。所以保持小批量操作和结果集的干净,是一个非常好的习惯。